Le reti neurali
In questo articolo si introducono le reti neurali spiegandone la struttura ed il processo di apprendimento.
La struttura di una rete neurale artificiale
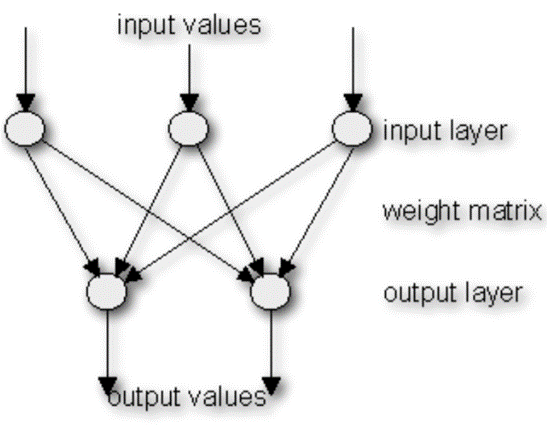
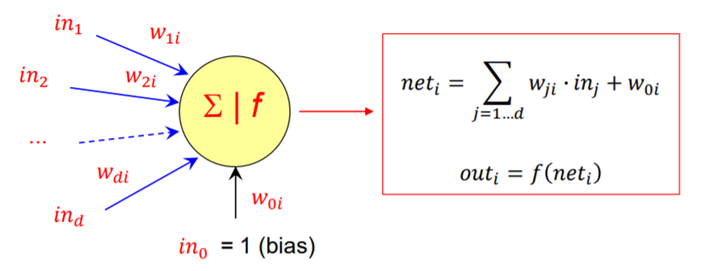
Una rete neurale artificiale (in inglese Artificial Neural Network, ANN) è un modello matematico di un sistema di ottimizzazione ispirato dal funzionamento del cervello umano e cerca di simularne il processo di apprendimento. Il termine artificiale sta ad indicare che le reti neurali sono implementate in programmi per computer che sono in grado di gestire il gran numero di calcoli necessari durante il processo di apprendimento. Una ANN è una struttura complessa costituita da tante unità elementari di calcolo che prendono il nome di neuroni, per l’analogia con il cervello umano. Il primo modello di neurone artificiale fu proposto nel 1943 da McCulloch e Pitts ed è schematizzabile come un combinatore lineare a soglia con input ed output binari ed in grado di eseguire computazioni logiche. Ogni neurone è caratterizzato da diversi elementi:
- “in_1,in_2….in_d” sono i“d” ingressi che il neurone “i” riceve da assoni di neuroni afferenti;
- “w_1i,w_2i…..w_d1” sono i pesi (weight) che determinano l’efficacia delle connessioni sinaptiche dei dendriti, ossia forniscono una misura di quanto “contano” i vari input nel neurone (su tali pesi si agisce durante l’apprendimento);
- “w_0i” (detto bias) è un ulteriore peso che si considera collegato ad un input fittizio con valore sempre costante, questo peso è utile per tarare il punto di lavoro ottimale del neurone;
- è il livello di eccitazione globale del neurone (potenziale interno);
- f(·) è la funzione di attivazione che determina il comportamento del neurone (ovvero il suo output ) in funzione del suo livello di eccitazione “net_i”.
Nel caso più semplice (e più biologicamente plausibile) la funzione di attivazione è una funzione a soglia Ɵ: se la somma pesata degli input è maggiore di una certa soglia t, allora il neurone risulta attivato (output 1), altrimenti risulta inibito.
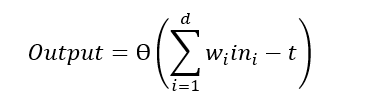
dove Ɵ è la funzione di Heaviside, detta anche funzione a gradino unitaria: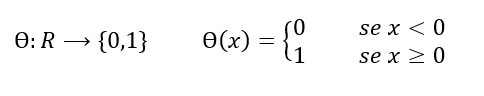
Questo semplice neurone si chiama Percettrone (Perceptron), introdotto da Rosenblatt nel 1958 e rappresenta il primo e più semplice schema di rete neurale.
Altre funzioni di attivazione comunemente utilizzate sono la funzione logistica (o sigmoide):
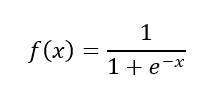
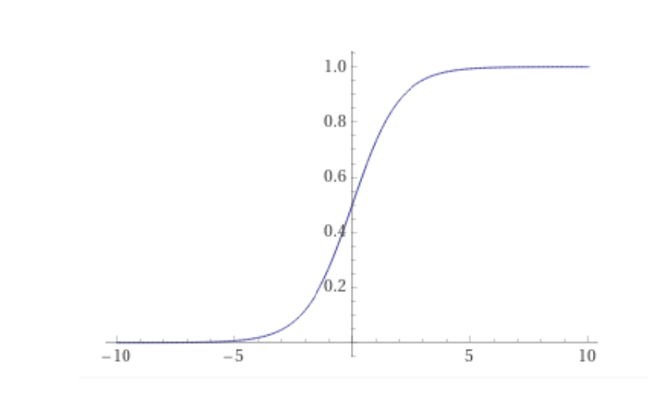
e la funzione tangente iperbolica:
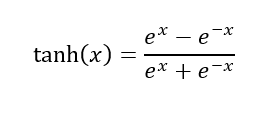
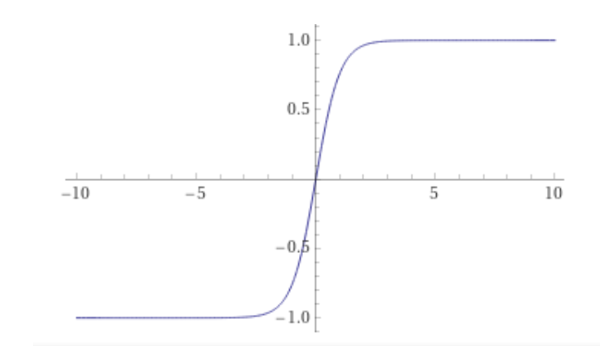
Queste funzioni sono così ampiamente utilizzate in quanto sono funzioni non lineari ma continue e differenziabili. Questo è dovuto al fatto che se si vuole che una rete neurale sia in grado di eseguire un mapping complesso dell’informazione di input è necessaria una funzione non lineare; mentre la continuità e la differenziabilità sono necessarie per la retropropagazione dell’errore.
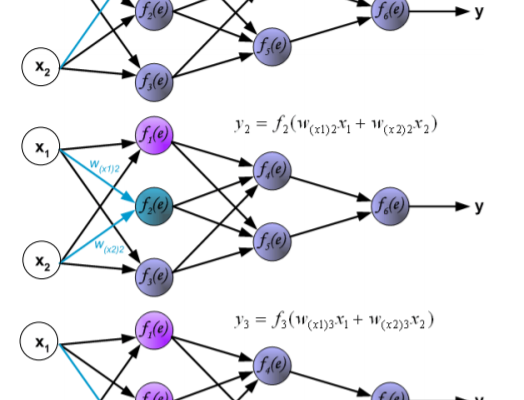
In una rete neurale, i neuroni sono raggruppati in strati (layers), denominati strati di neuroni (neuron layers). Di solito ogni neurone di uno strato è collegato a tutti i neuroni dello strato precedente e successivo, fatta eccezione per gli strati di input ed output. Le informazioni fornite da una rete neurale sono propagate layer-by-layer dallo strato di input a quello di output attraverso uno o più strati nascosti (hidden). Lo strato di input si preoccupa di trattare gli ingressi in modo da adeguarli alle richieste dei neuroni, lo strato nascosto (generalmente è uno) si occupa invece dell’elaborazione vera e propria, mentre lo strato di output raccoglie i risultati e li adatta in modo tale da renderli fruibili al programmatore.
Il processo di apprendimento di una rete neurale
Come accennato prima, le reti neurali cercano di simulare la capacità di apprendimento del cervello umano. A differenza del modello biologico, però, una rete neurale ha una struttura immutabile, costruita su un determinato numero di neuroni e un determinato numero di connessioni tra di loro (i pesi) che hanno certi valori; ciò che cambia nel processo di apprendimento sono i valori di tali pesi.
Ci sono tre grandi paradigmi di apprendimento, ciascuno corrispondente ad un particolare compito astratto di apprendimento; si tratta dell’apprendimento supervisionato, apprendimento non supervisionato e apprendimento per rinforzo.
Nell’apprendimento supervisionato, alla rete viene fornito un insieme di dati per l’addestramento (training set) comprendente esempi tipici di ingressi con le relative uscite corrispondenti; in tal modo la rete può imparare ad inferire la relazione che li lega. Successivamente la rete è addestrata con un opportuno algoritmo, il quale utilizza tali dati allo scopo di modificare i pesi ed altri parametri della rete stessa in modo tale da minimizzare l’errore di previsione relativo all’insieme di addestramento. Se l’addestramento ha successo, la rete impara a riconoscere la relazione incognita che lega le variabili d’ingresso a quelle d’uscita, ed è quindi in grado di fare previsioni anche laddove l’uscita non è nota a priori; in altri termini, l’obiettivo finale dell’apprendimento supervisionato sarà la previsione del valore d’uscita per ogni valore valido d’ingresso, basandosi soltanto su un numero limitato di esempi. Questo tipo di apprendimento è utilizzato per risolvere problemi di regressione o classificazione.
L’apprendimento non supervisionato è invece basato su algoritmi d’addestramento che modificano i pesi della rete facendo esclusivamente riferimento ad un insieme di dati che include le sole variabili d’ingresso. Tali algoritmi tentano di raggruppare i dati d’ingresso e di individuare quindi degli opportuni cluster rappresentativi dei dati stessi, facendo uso tipicamente di metodi topologici o probabilistici. Pertanto le reti neurali non supervisionate non hanno uscite predefinite, ossia il risultato del processo di apprendimento non può essere determinato a priori. Questo tipo di apprendimento è adatto per la compressione di dati o l’ottimizzazione di risorse.
Nell’apprendimento per rinforzo, infine, un opportuno algoritmo si prefigge lo scopo di individuare un certo modus operandi a partire da un processo di osservazione dell’ambiente esterno; ogni azione ha un impatto sull’ambiente, e l’ambiente produce una retroazione che guida l’algoritmo stesso nel processo di apprendimento. Tale classe di problemi postula un agente, dotato di capacità di percezione, che esplora un ambiente nel quale intraprende una serie di azioni; l’ambiente stesso fornisce in risposta un incentivo o un disincentivo, a seconda dei casi. Gli algoritmi per l’apprendimento per rinforzo tentano in definitiva di determinare una politica tesa a massimizzare gli incentivi cumulati ricevuti dall’agente nel corso della sua esplorazione del problema. L’apprendimento con rinforzo differisce da quello supervisionato poiché non sono mai presentate delle coppie input-output di esempi noti, né si procede alla correzione esplicita di azioni subottimali. Questo tipo di apprendimento viene usato per gestire problemi sequenziali o di controllo.
Il tipo più semplice di algoritmo utilizzato nell’apprendimento supervisionato è il forward propagation (propagazione in avanti), ossia le informazioni possono viaggiare solo attraverso strati successivi della rete, ma non attraverso lo stesso strato o strati precedenti.
L’algoritmo funziona nel seguente modo:
- Si impostano tutti i pesi a valori casuali compresi tra -1 e +1;
- Si fornisce un pattern (modello) di ingresso ai neuroni del livello di input;
- Viene attivato ogni neurone dello strato successivo nel modo seguente:
- si moltiplicano i valori di peso delle connessioni che portano al neurone con i valori di output dei neuroni precedenti;
- si sommano questi valori;
- il risultato viene passato ad una funzione di attivazione che calcola il valore di uscita del neurone;
- Si ripete questa operazione fino a quando lo strato di uscita non viene raggiunto;
- Si confronta il pattern di uscita calcolato con il pattern previsto e si calcola l’errore;
- Vengono modificati tutti i pesi aggiungendo il valore di errore ai vecchi valori di peso;
- Si torna al punto 2;
- L’algoritmo termina infine se tutti i pattern di output corrispondono ai loro pattern previsti, altrimenti si ripete l’epoca di apprendimento.
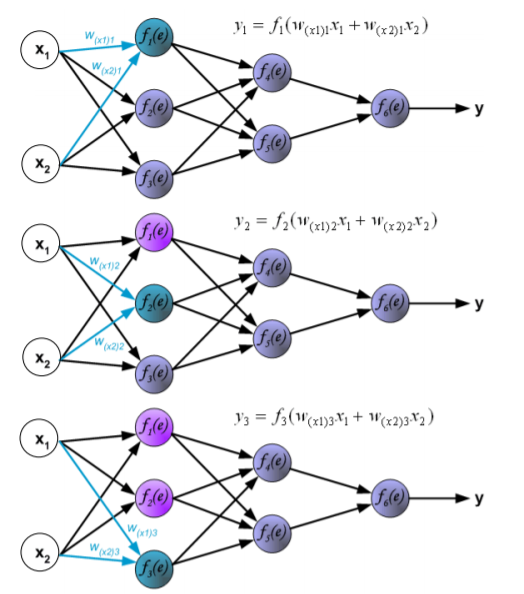

Il più comune algoritmo utilizzato nelle reti ad apprendimento supervisionato è il backward propagation o più semplicemente backpropagation (propagazione all’indietro), ossia le informazioni possono viaggiare anche attraverso strati precedenti della rete. Questo algoritmo utilizza l’errore di output per cambiare i valori dei pesi a ritroso; per ottenere l’errore deve essere stata precedentemente eseguita una fase di forward propagation, durante la quale i neuroni vengono attivati utilizzando la funzione di attivazione.
L’algoritmo funziona nel modo seguente:
- Viene eseguita la fase di forward propagation per un pattern di input e viene calcolato l’errore di uscita;
- Si propaga all’indietro l’errore verso il livello di input, addizionando ad ogni peso un valore positivo o negativo determinato dalla sua influenza nella formazione dell’errore;
- Si torna al punto 1;
- Se tutti i pattern di output corrispondono ai target l’algoritmo termina, altrimenti si ripete l’epoca di apprendimento.
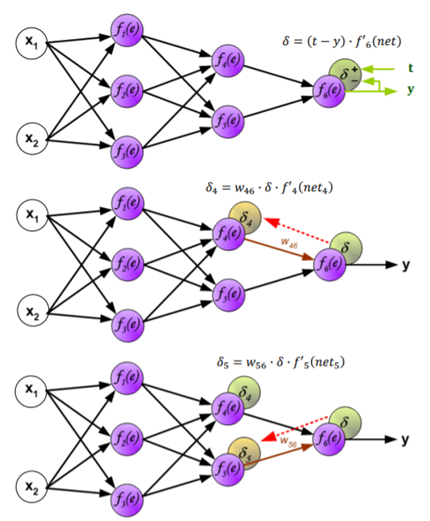
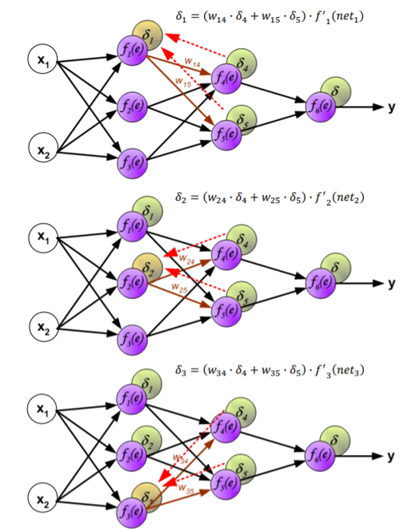
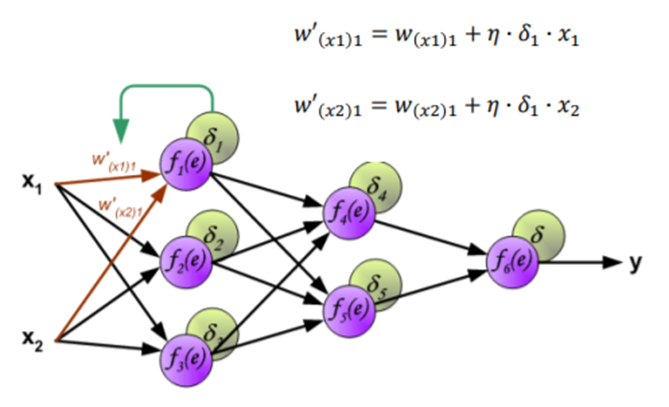
Per quanto riguarda le reti non supervisionate, invece, il più comune algoritmo di apprendimento è il SOM (Self Organizing Maps).
L’algoritmo SOM funziona nel modo seguente:
- Si definisce l’intervallo dei valori di input.
- Vengono impostati tutti i pesi a valori casuali presi nel campo dei valori di ingresso;
- Viene definita l’area iniziale (raggio) di attivazione;
- Si prende un valore a caso dal set di input e lo si passa ai neuroni dello strato di input;
- Si determina il neurone più attivo sulla mappa:
- si moltiplica l’uscita del livello di input con i valori dei pesi;
- il neurone mappa con il maggior valore risultante è detto essere il più attivo;
- si calcola il valore di feedback di ogni altro neurone mappa utilizzando la funzione di Gauss:
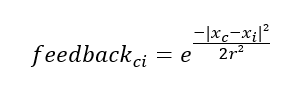
dove
- “x_c” è la posizione del neurone più attivato (centroide);
- “x_i” sono le posizioni degli altri neuroni della mappa;
- “r” è l’area di attivazione (raggio);
6. Si ottengono i nuovi valori dei pesi con la formula:
![]()
7. Si riduce l’area di attivazione;
8. Si torna al punto 4;
9. L’algoritmo termina se l’area di attivazione è più piccola di un valore specificato.
Potrebbero interessarti anche i seguenti articoli:
Fonti
- www.terna.it/it
- www.studioninarello.it/efficienza-energetica/la-generazione-distribuita/
- www.aerel.info/struttura/tecnologie/generazione-distribuita
- “A spiking neural network (SNN) forecast engine for short-term electrical load forecasting”, Santosh Kulkarni , Sishaj Simon, K. Sundareswaran (2013)
- bias.csr.unibo.it/maltoni/ml/DispensePDF/8_ML_RetiNeurali.pdf
- www.crescenziogallo.it/unifg/dottorato-medicina-traslazionale- 2018/Reti%20neurali%20artificiali%20-%20Concetti%20base.pdf
- www.di.univr.it/documenti/OccorrenzaIns/matdid/matdid833568.pdf
- vision.unipv.it/IA/aa2001-2002/10-RetiNeurali.pdf
- www.illuminamente.org/dokuwiki/lib/exe/fetch.php?media=neurali:reti3.pdf
- tesi.cab.unipd.it/64862/1/tesi pdf
- download.terna.it/terna/Annuario%20Statistico%202018_8d7595e944c2546.pdf
- www.mathworks.com/products/deep-learning.html
- www.terna.it/it/sistema-elettrico/transparency-report/download-center
- “Forecasting Hourly Electricity Load Profile Using Neural Networks”, Mashud Rana, Irena Koprinska, Alicia Troncoso (2014) – reti neurali – reti neurali.